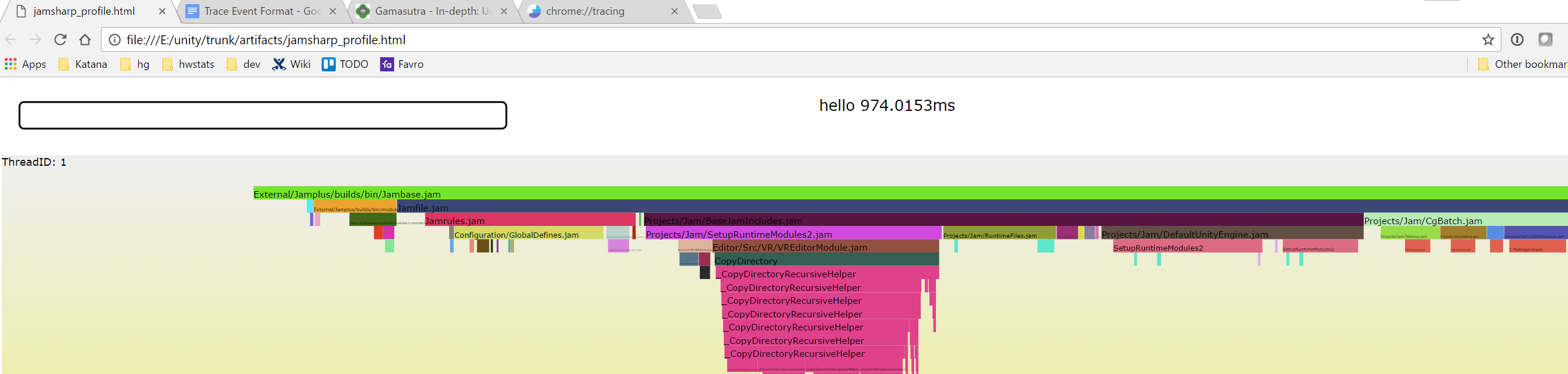
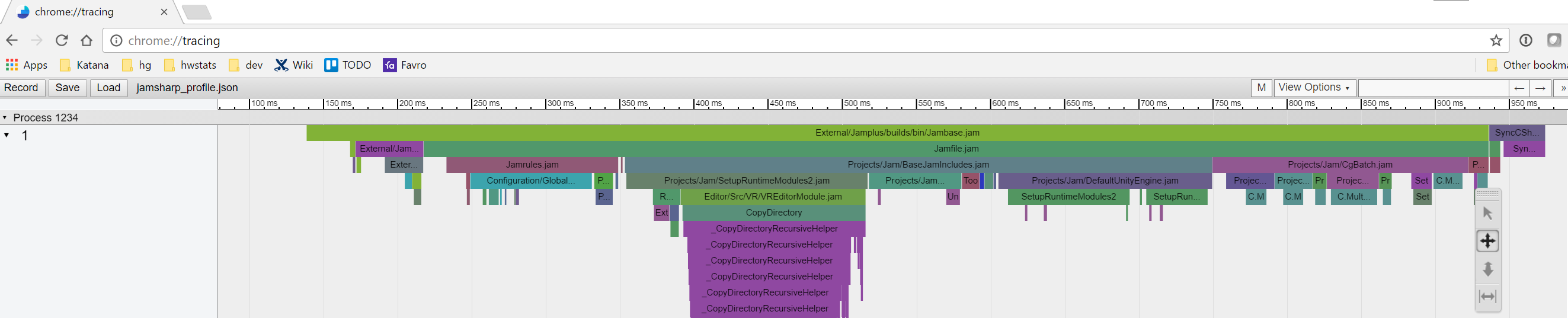
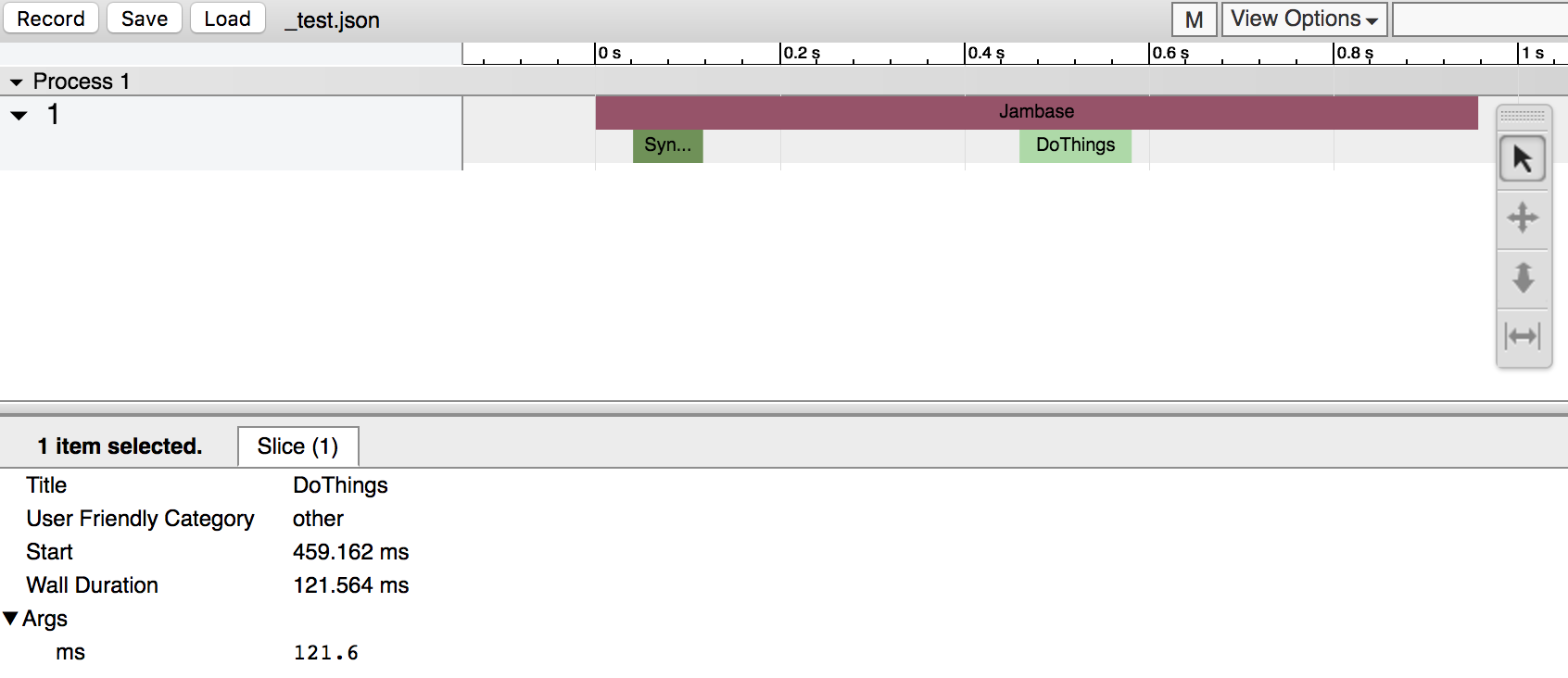
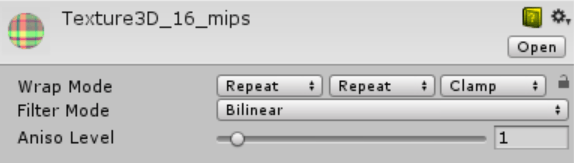
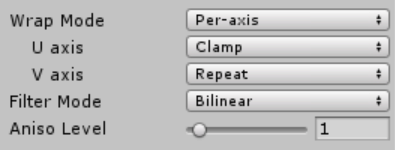
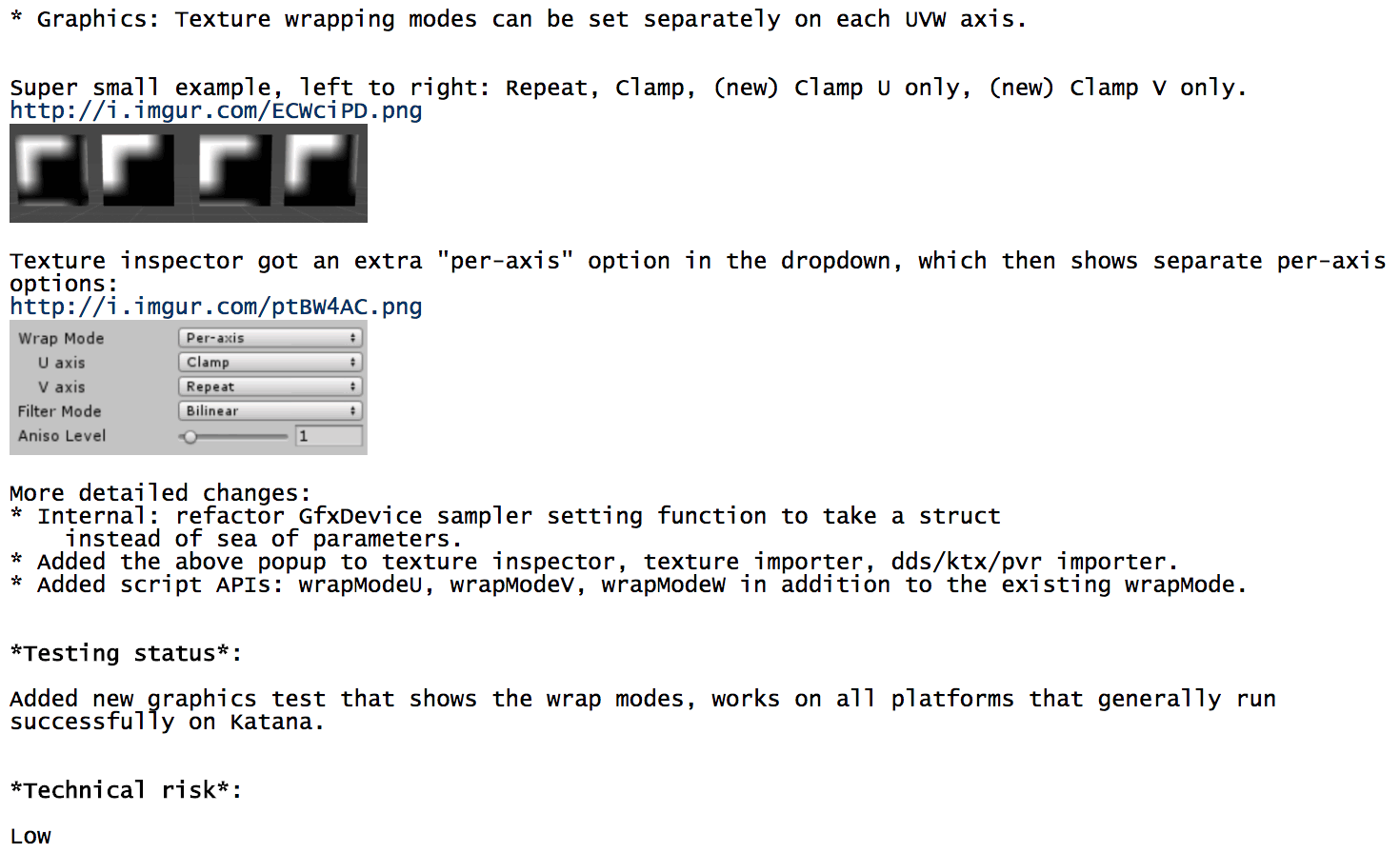
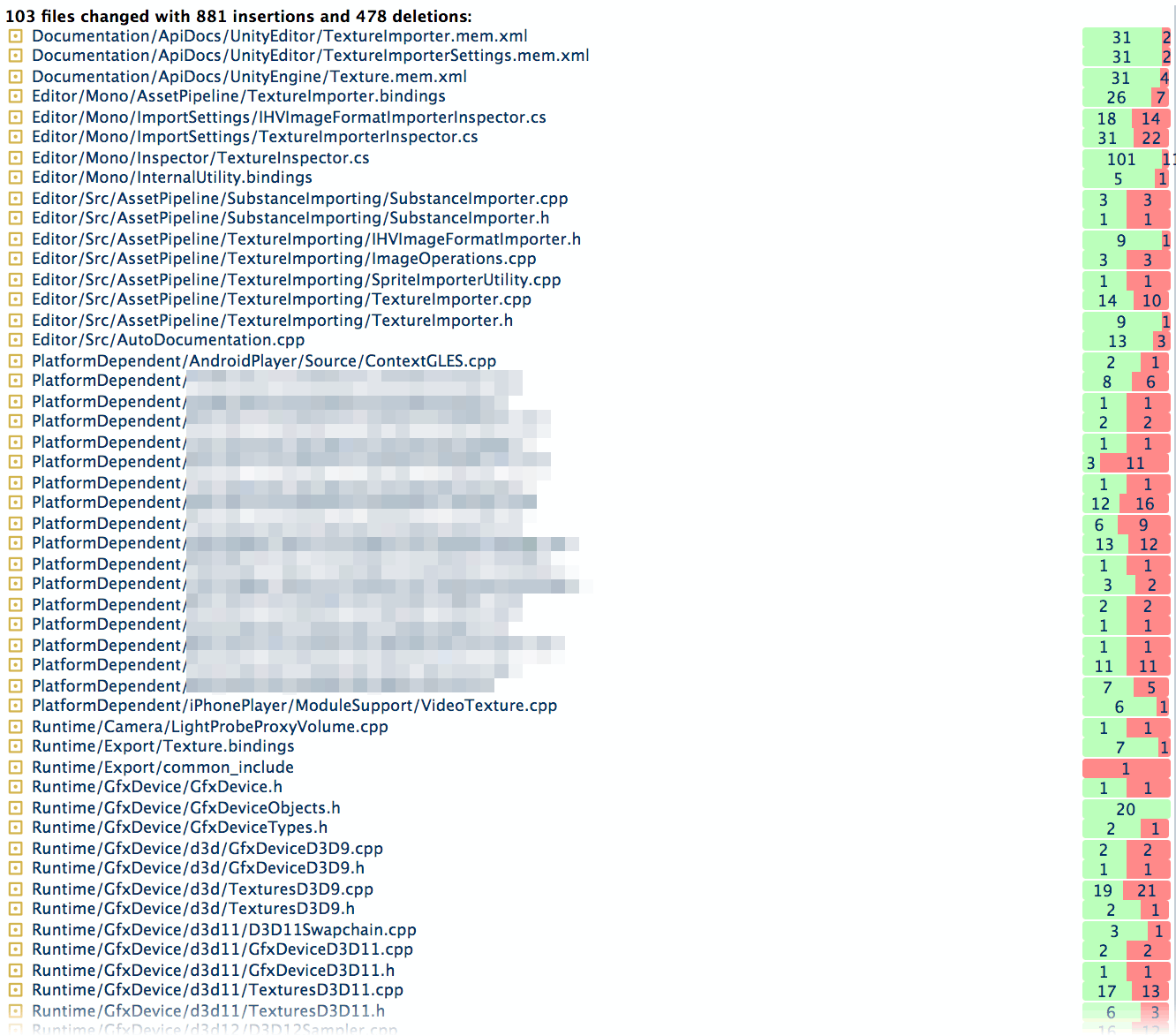
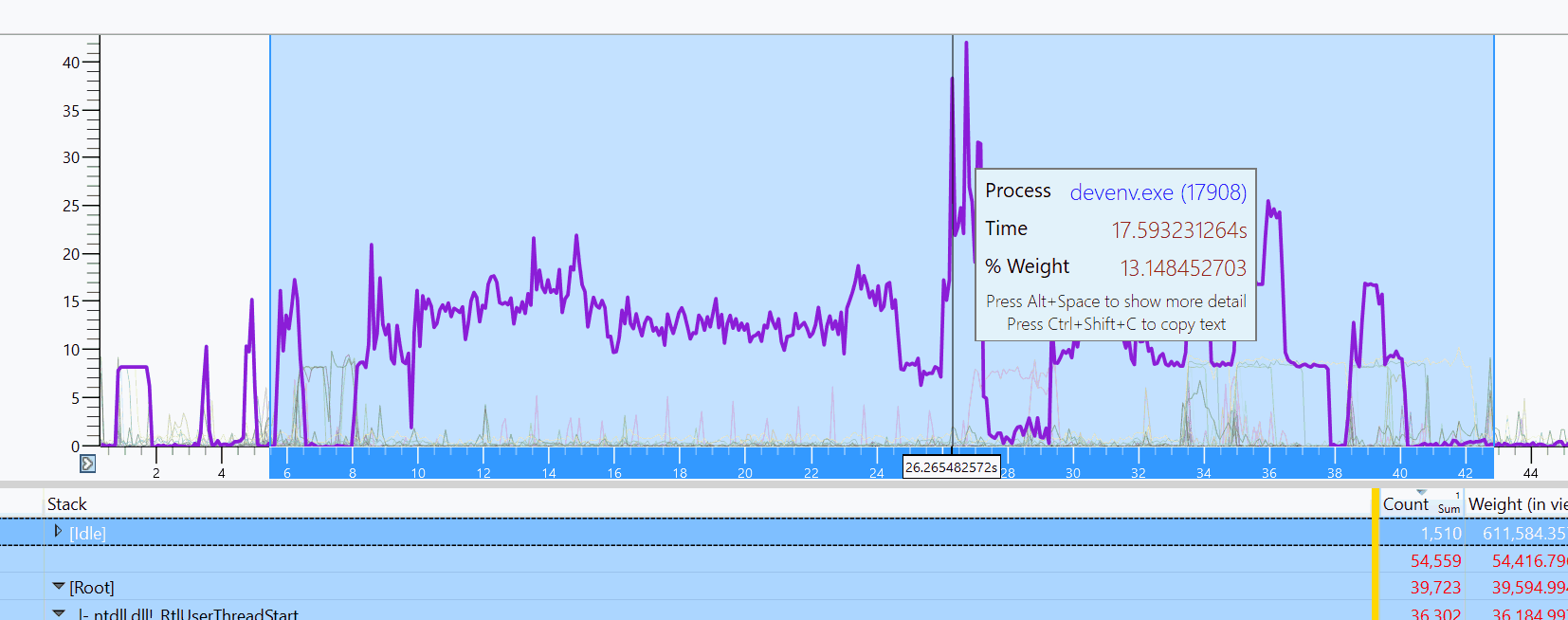
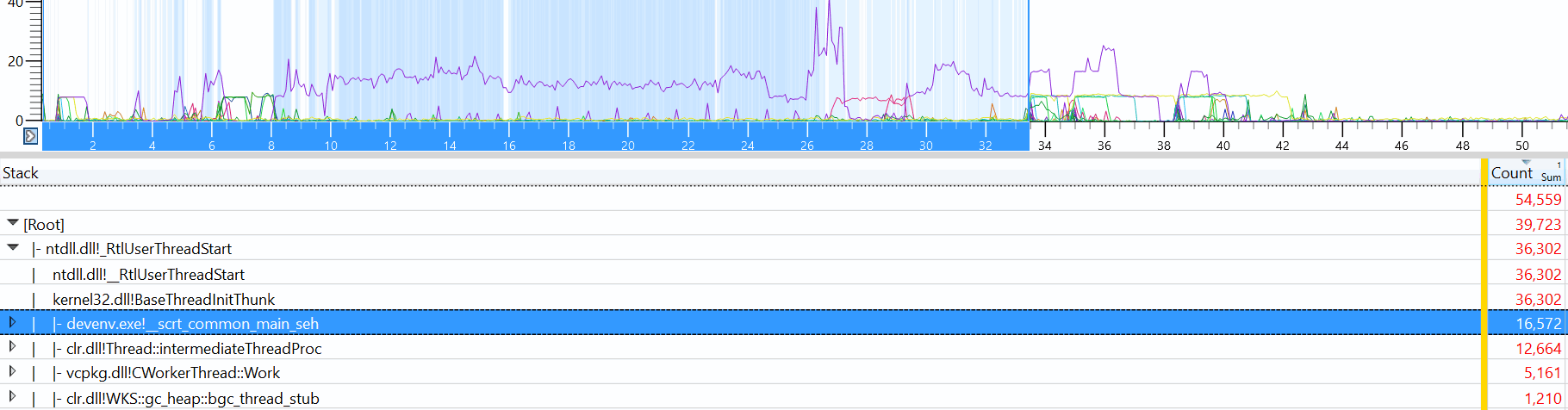
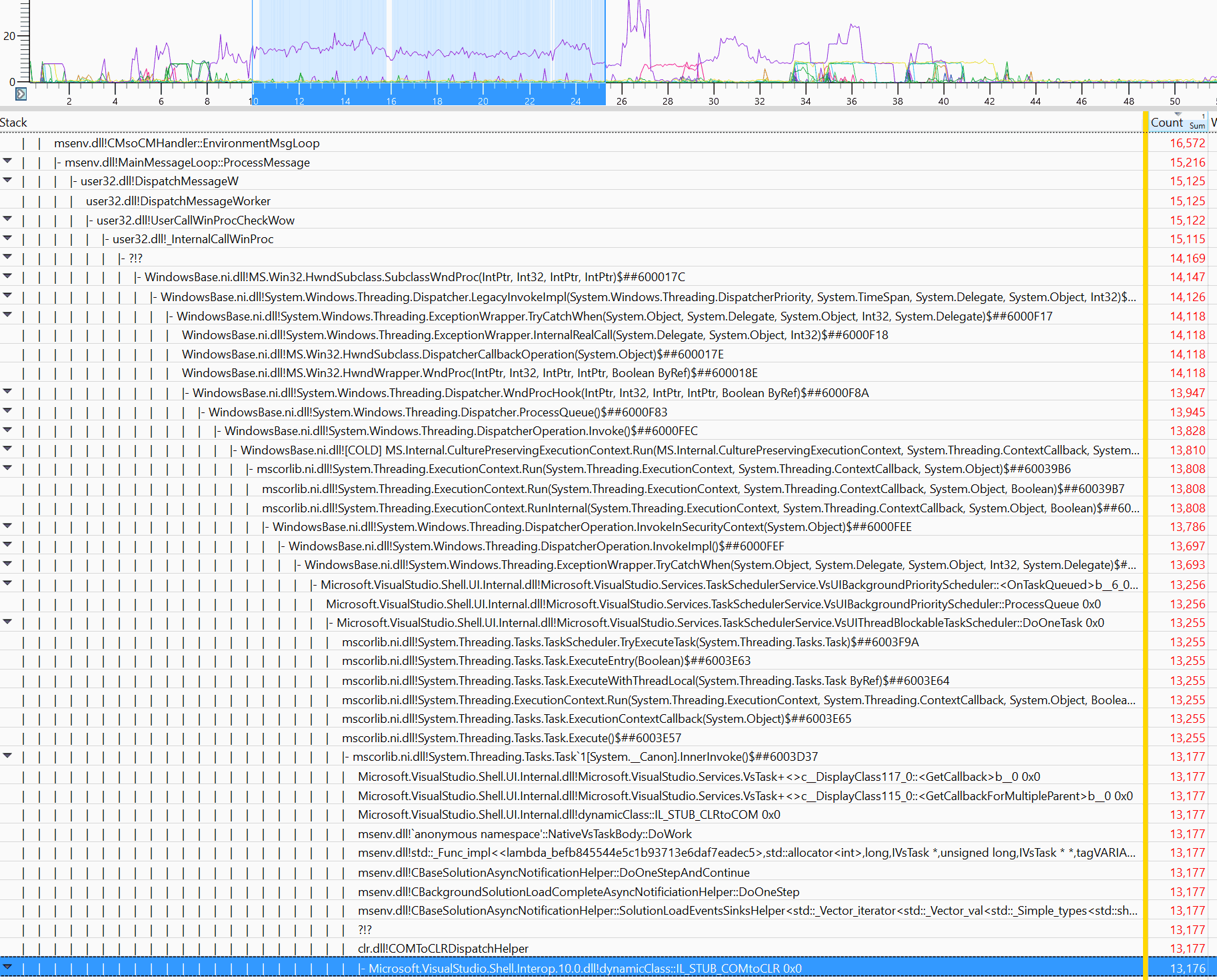
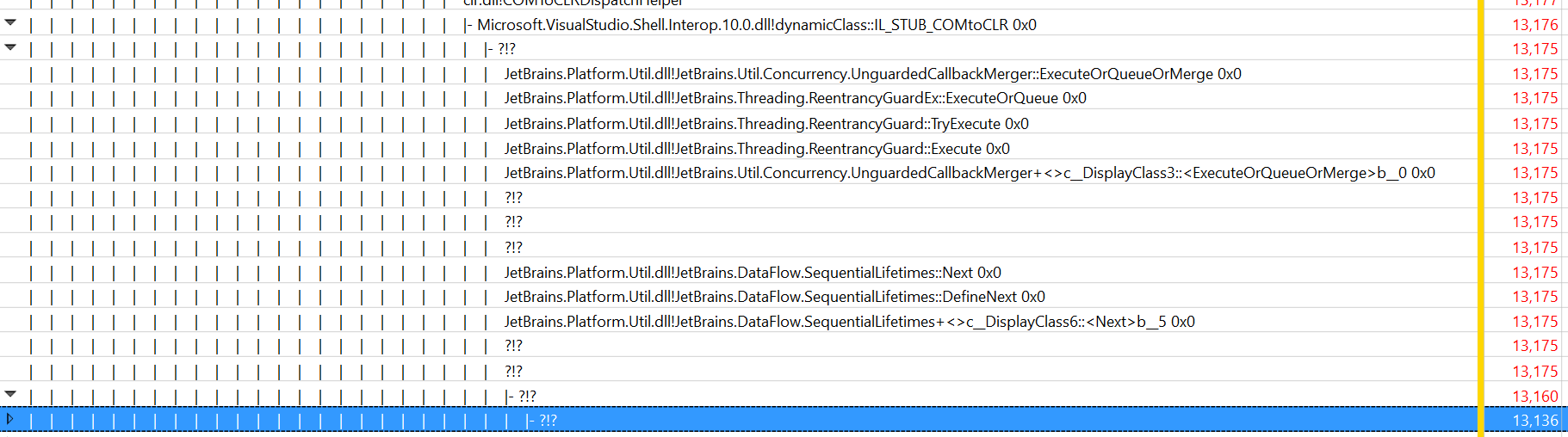
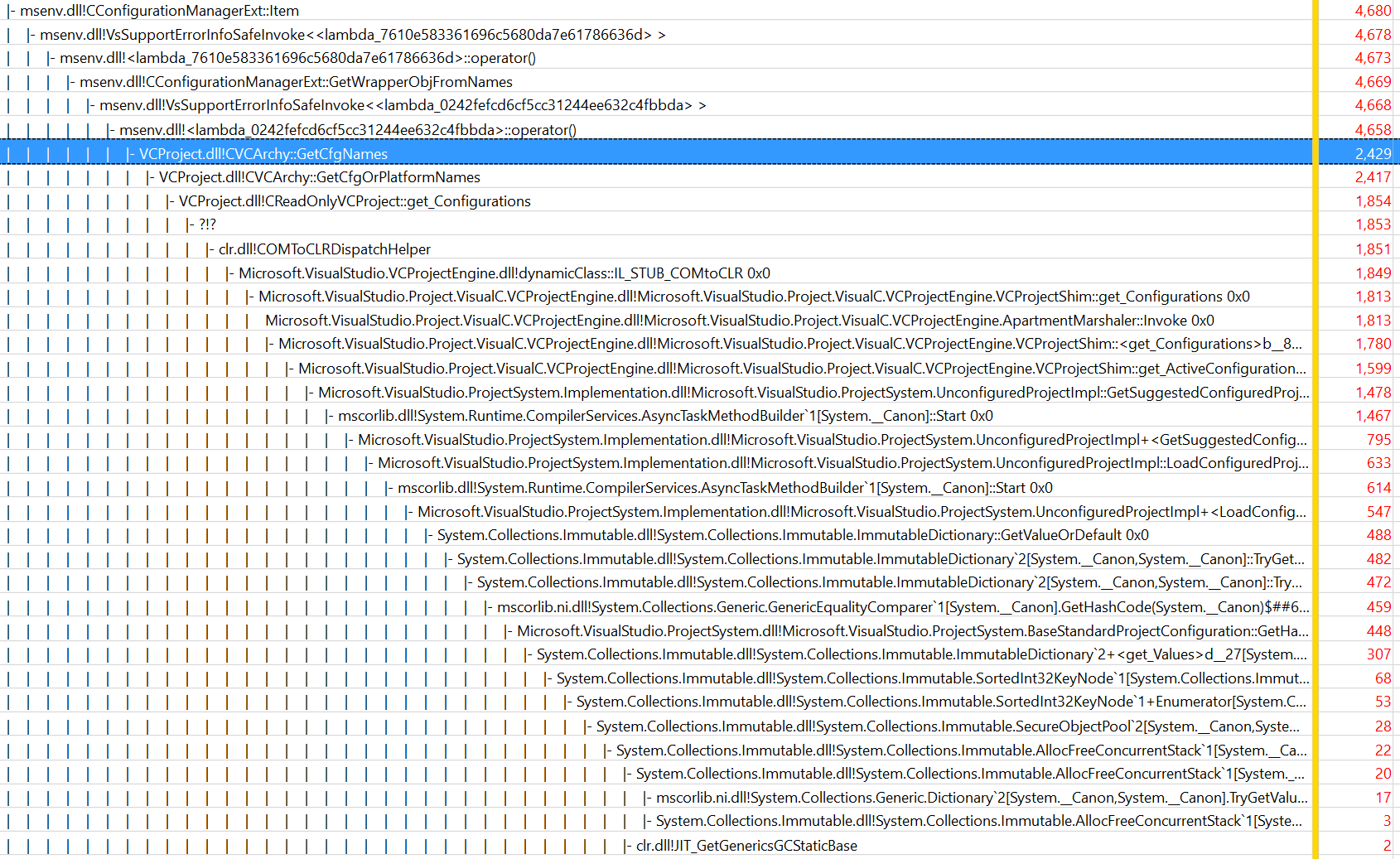
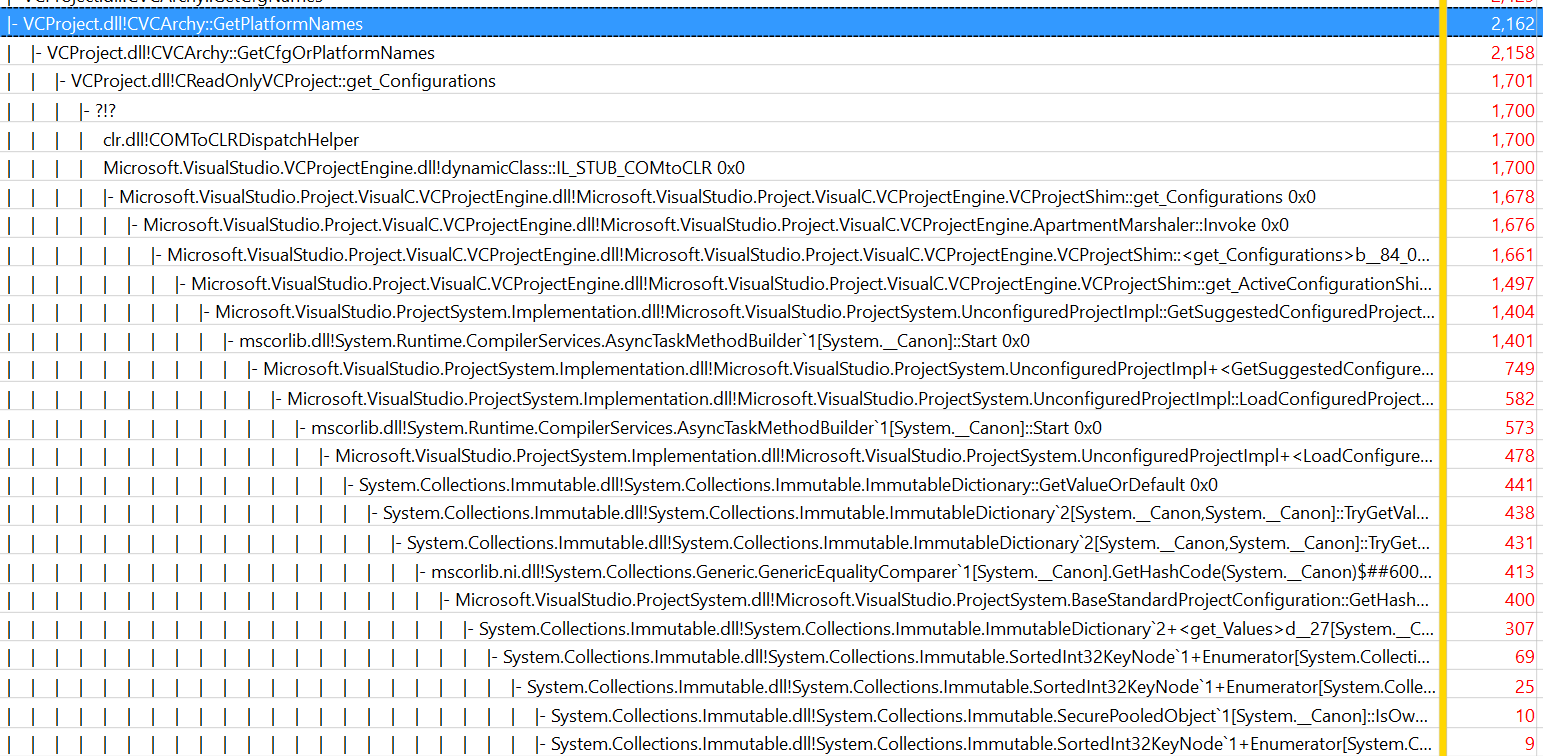
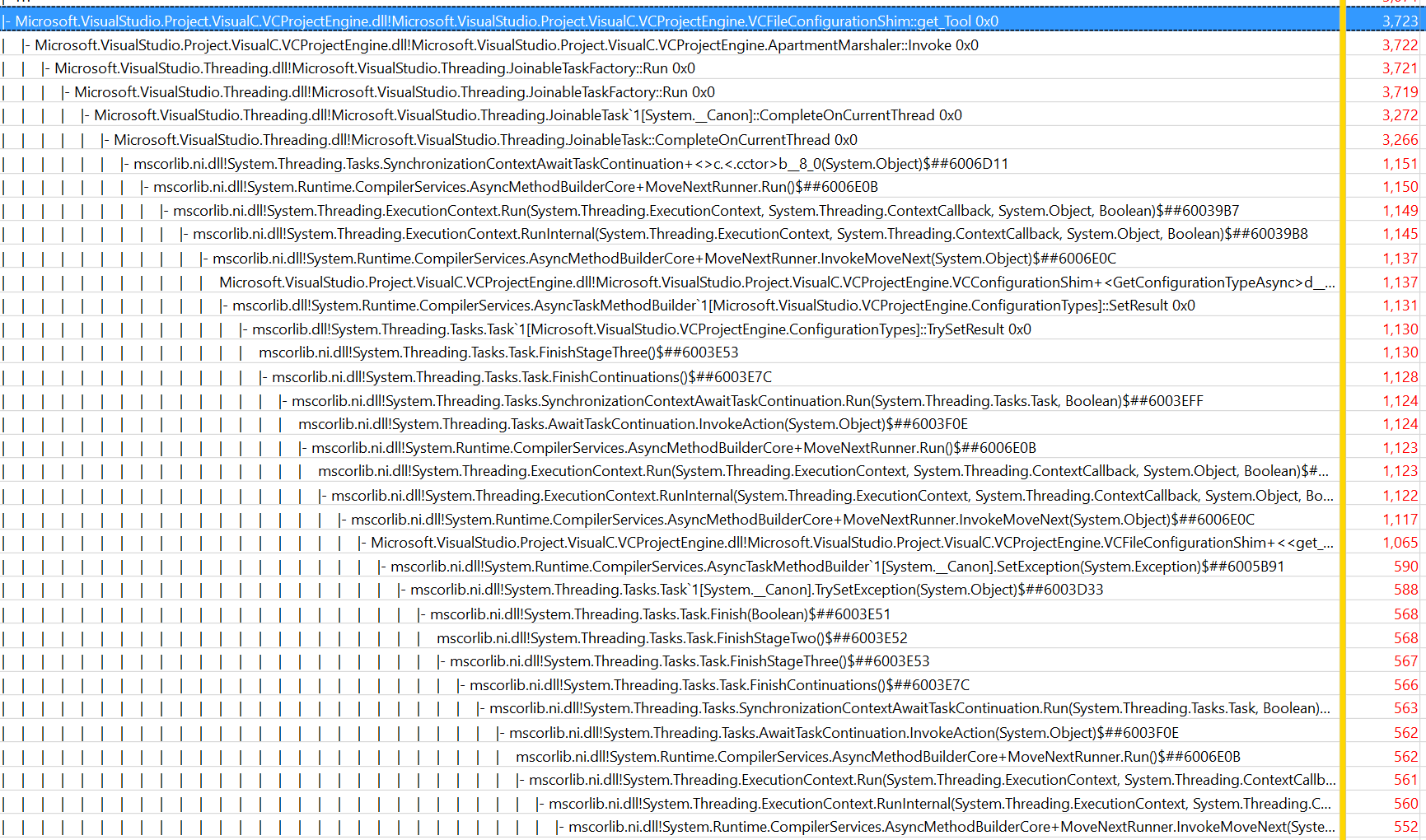
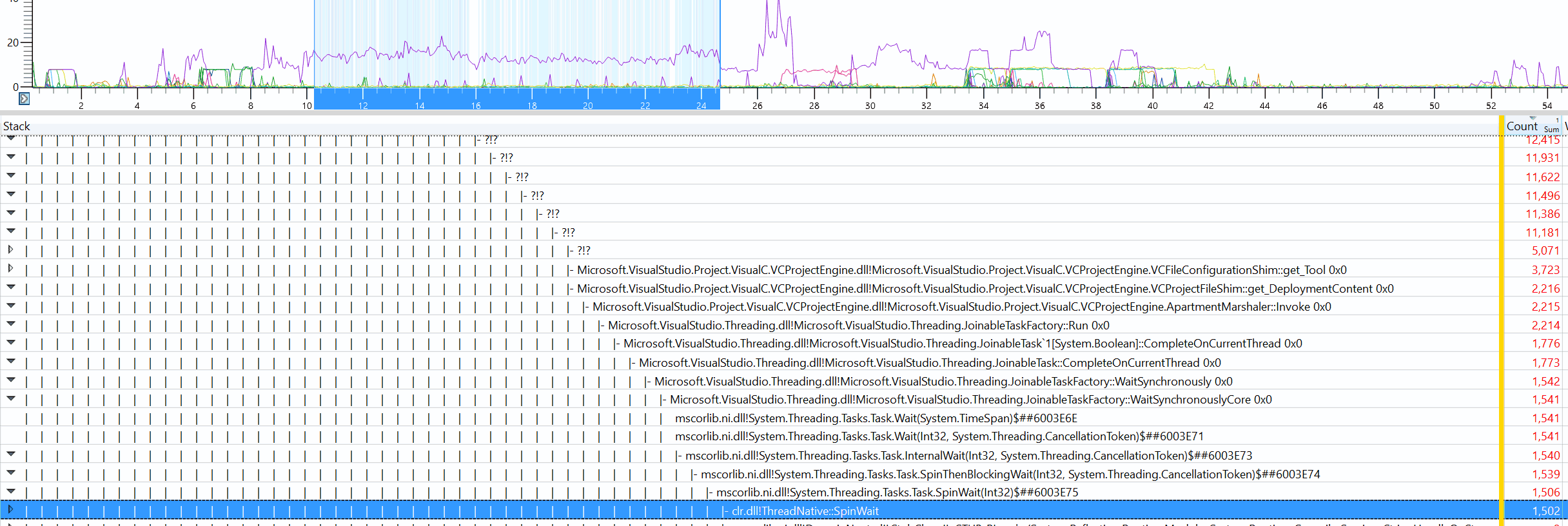
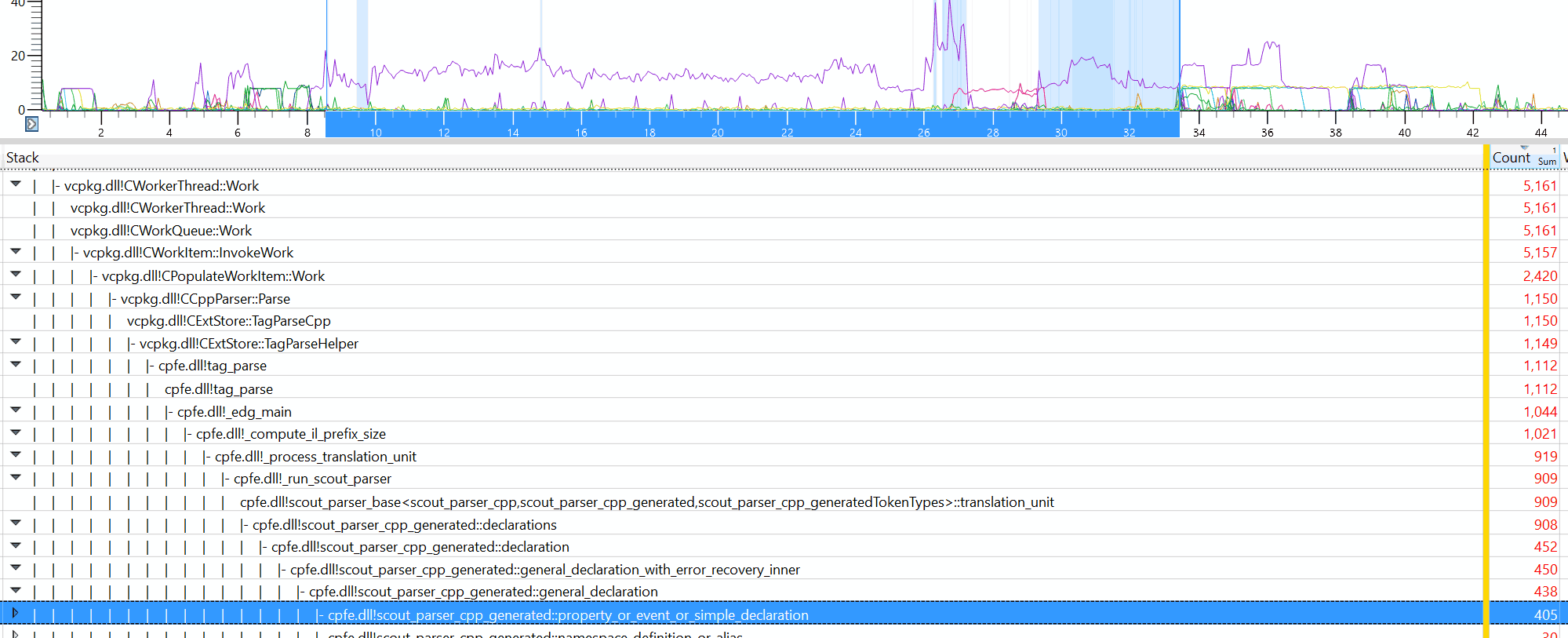
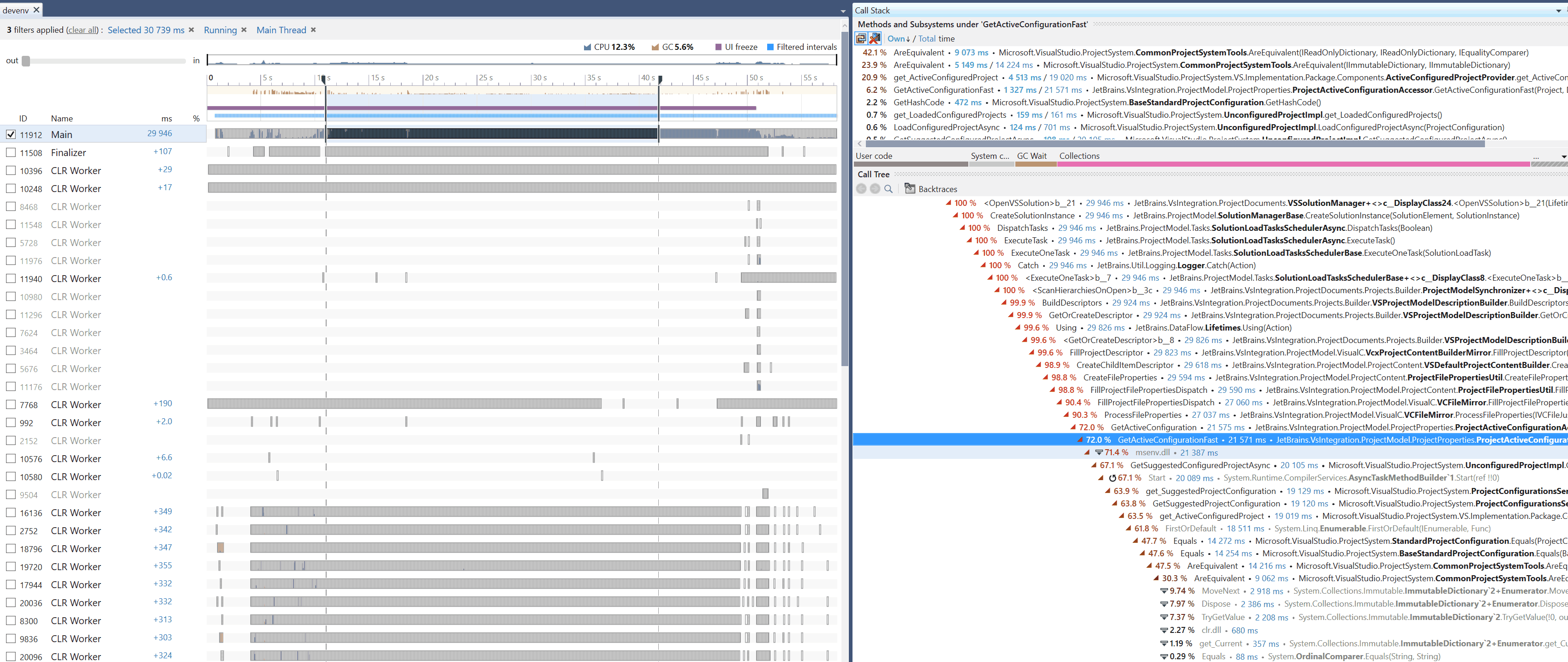
I don’t have any technical insights to share right now, so you’ll have to bear with me blabbering about random stuff!
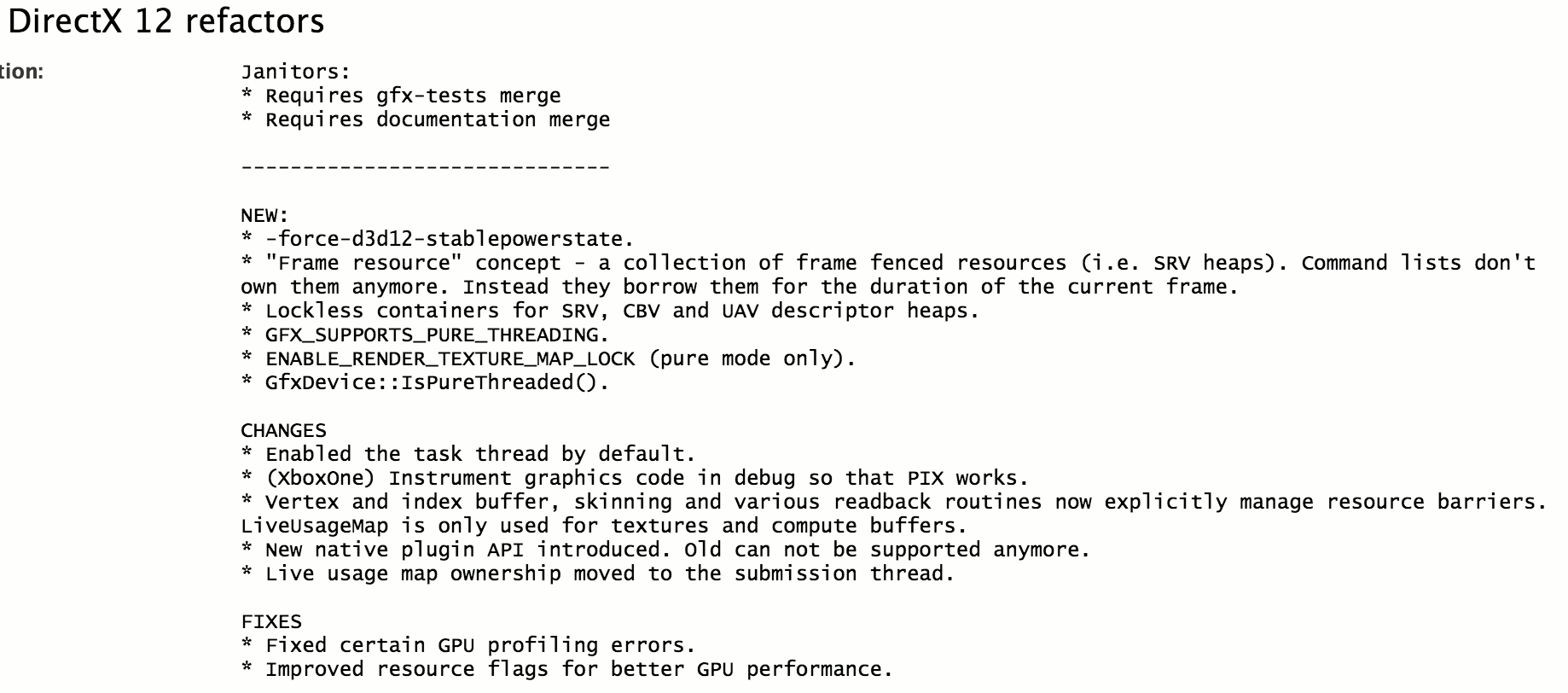
Unity Work
By now it’s been 11 years at Unity (see 10 Years at Unity a year ago), and the last year has been interesting. Started out as written in that blog post – that I will be mostly doing plumbing & fixing and stuff.
But then at some point we had a mini-hackweek of “what should the future rendering pipeline of Unity should be?”, and it went quite well. So a team with tasks of “build building blocks for future rendering pipelines” and “modernize low level graphics code” was built, see more on Scriptable Render Loops google doc and corresponding github project. I’ve been doing mostly, well, plumbing there, so nothing new on that front :) – but overall this is very exciting, and if done well could be a big improvement in how Unity’s graphics engine works & what people can do with it.
I’ve also been a “lead” of this low level graphics team (“graphics foundation team” as we call it), and (again) realized that I’m the worst lead the world has ever seen. To my fellow colleagues: sorry about that (シ. .)シ So I stopped being a lead, and that is now in the capable hands of @stramit.
 Each year I write a “summary of stuff I’ve done”, mostly for myself to see whether my expectations/plans matched reality.
This year a big part in the mismatch has been because at start of year I did not know we’d go big into“let’s do scriptable render loops!”, otherwise it went as expected.
Each year I write a “summary of stuff I’ve done”, mostly for myself to see whether my expectations/plans matched reality.
This year a big part in the mismatch has been because at start of year I did not know we’d go big into“let’s do scriptable render loops!”, otherwise it went as expected.
Day to day it feels a bit like “yeah, another day of plumbing”, but the summary does seem to indicate that I managed to get a decent amount of feature/improvement work done too. Nothing that would set the world on fire, but not bad either! Though thinking about it, after 2016, maybe the world could do with less things that set it on fire…
 My current plan for next year is to continue working on scriptable render loops and whatever low level things they
end up needing. But also perhaps try some new area for a bit, something where I’m a newbie and would have to learn
some new things. We’ll see!
My current plan for next year is to continue working on scriptable render loops and whatever low level things they
end up needing. But also perhaps try some new area for a bit, something where I’m a newbie and would have to learn
some new things. We’ll see!
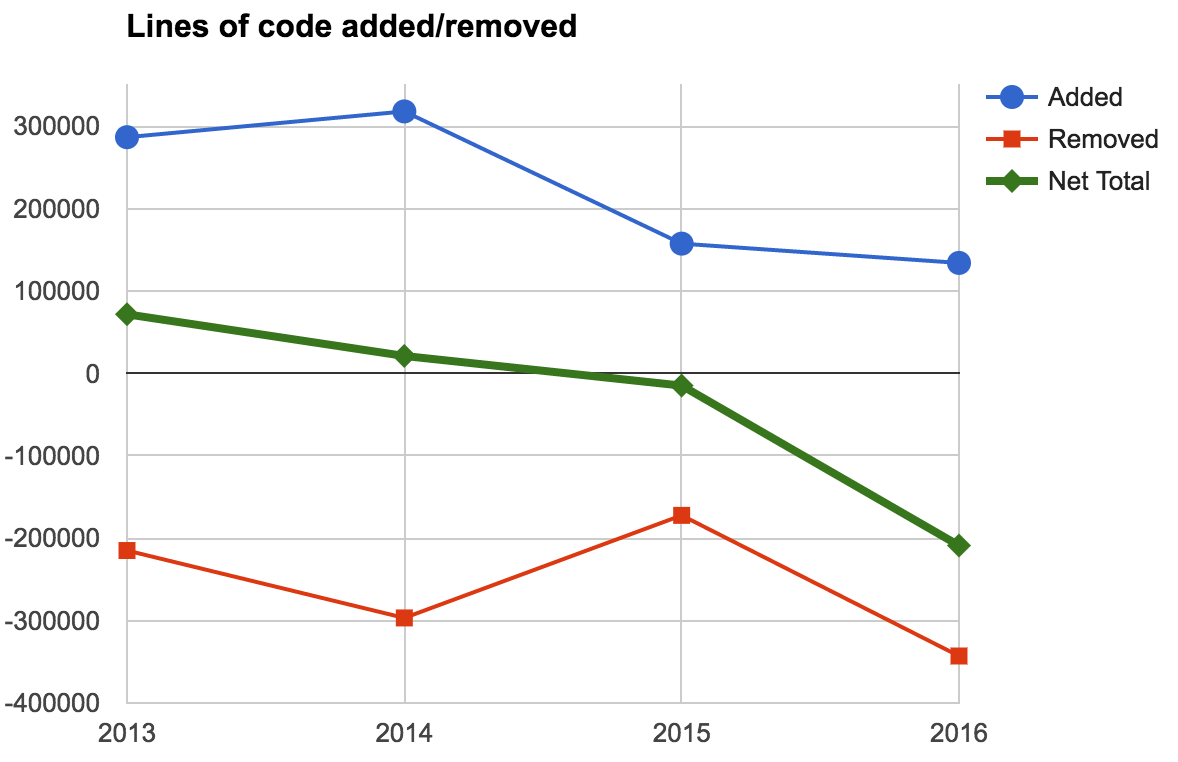
Oh, and extrapolating from the trend, I should effectively remove close to half a million lines of code this year. My fellow colleagues: brace yourselves :)
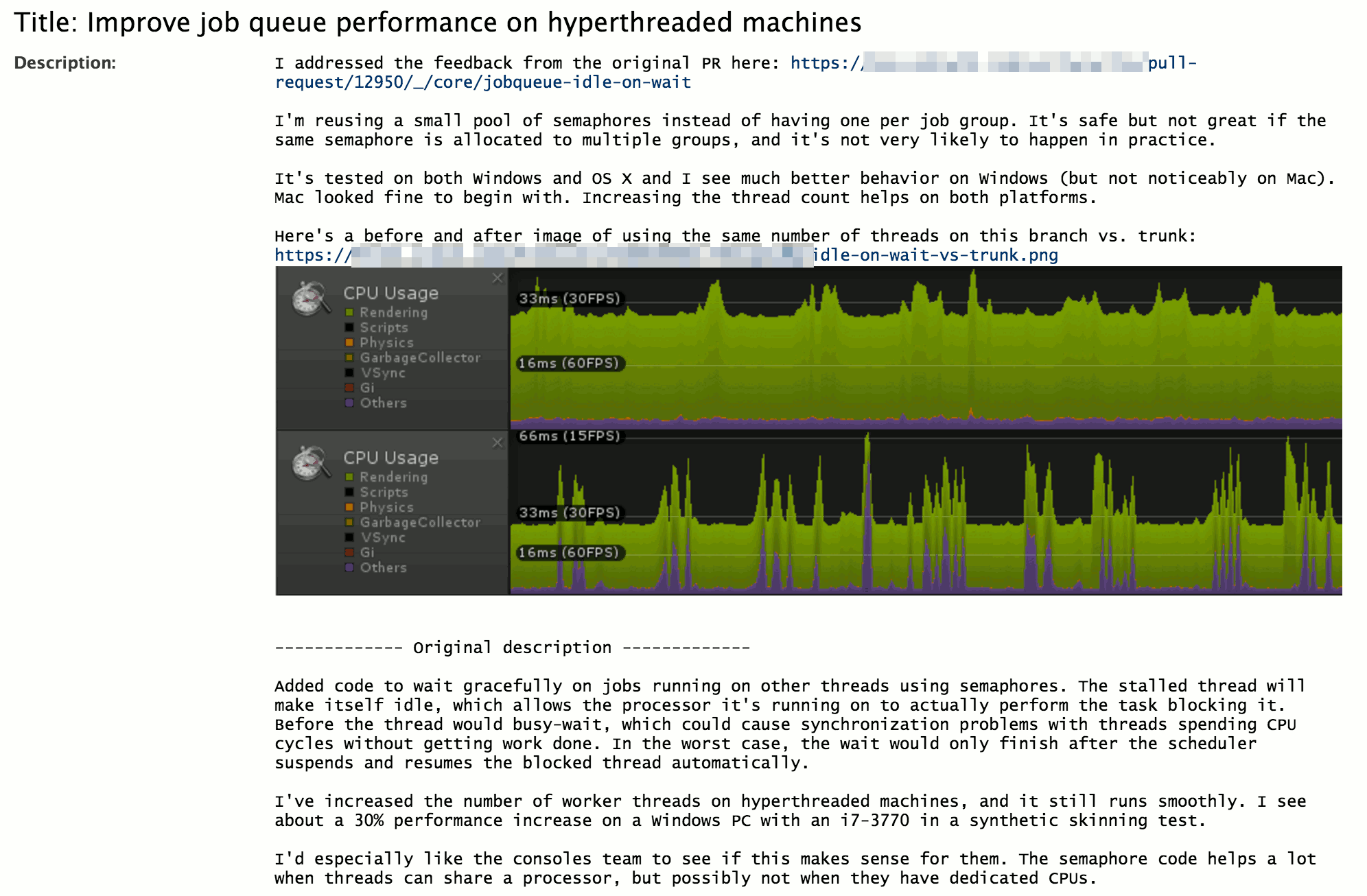
Open Source
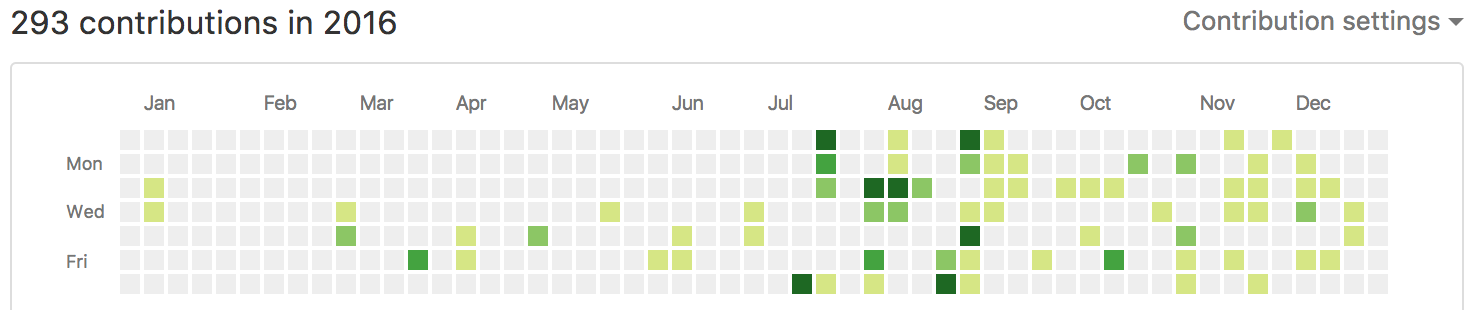 My github contributions are not terribly impressive, but I managed to do better than in 2015.
My github contributions are not terribly impressive, but I managed to do better than in 2015.
- Primarily SMOL-V, a SPIR-V shader compressor for Vulkan. It’s used in Unity now, and as far as I know, also used in two non-Unity game productions. If you use it (or tried it, but it did not work or whatever), I’d be happy to know!
- Small amount of things in GLSL Optimizer andHLSL2GLSL, but with Unity itself mostly moving to a different shader compiler toolchain (HLSLcc at the moment), work there has been winding down. I did not have time or will to go through the PRs & issues there, sorry about that.
- A bunch of random tiny fixes or tweaks submitted to other github projects, nothing of note really.
Writing
 I keep on hearing that I should write more, but most of the time don’t feel like I have anything interesting to say.
So I keep on posting random lame jokes and stuff on twitter instead.
I keep on hearing that I should write more, but most of the time don’t feel like I have anything interesting to say.
So I keep on posting random lame jokes and stuff on twitter instead.
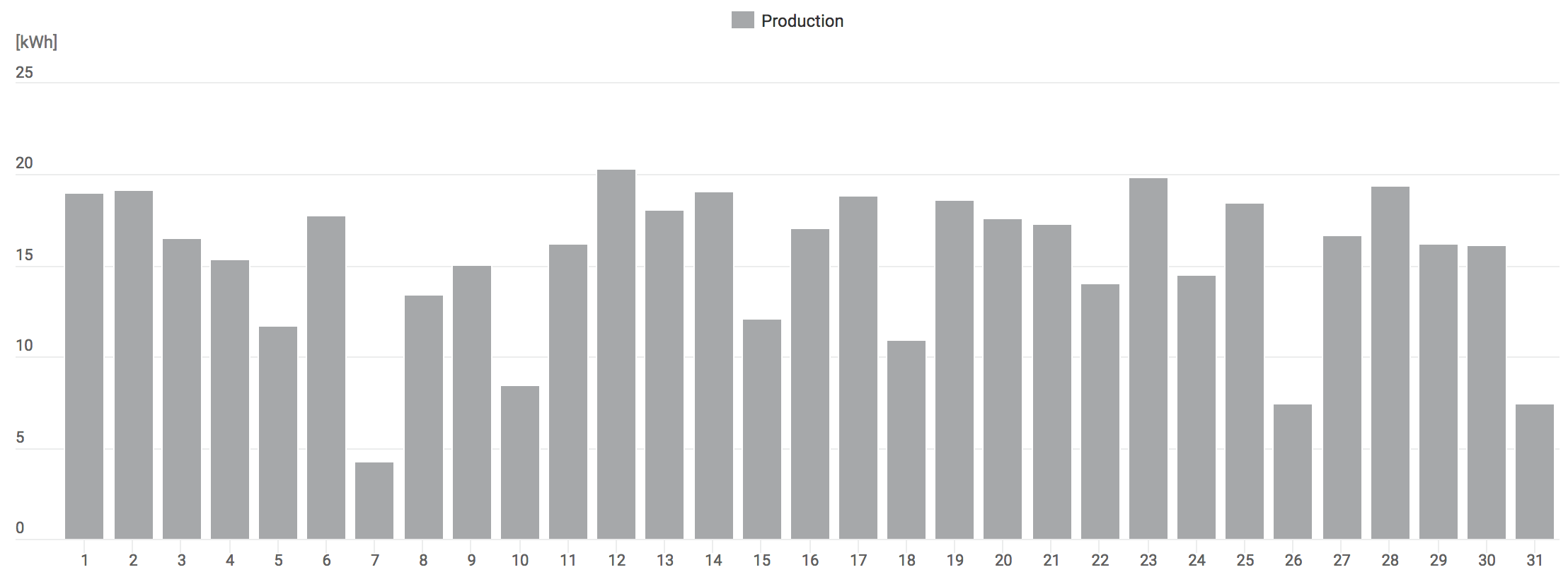
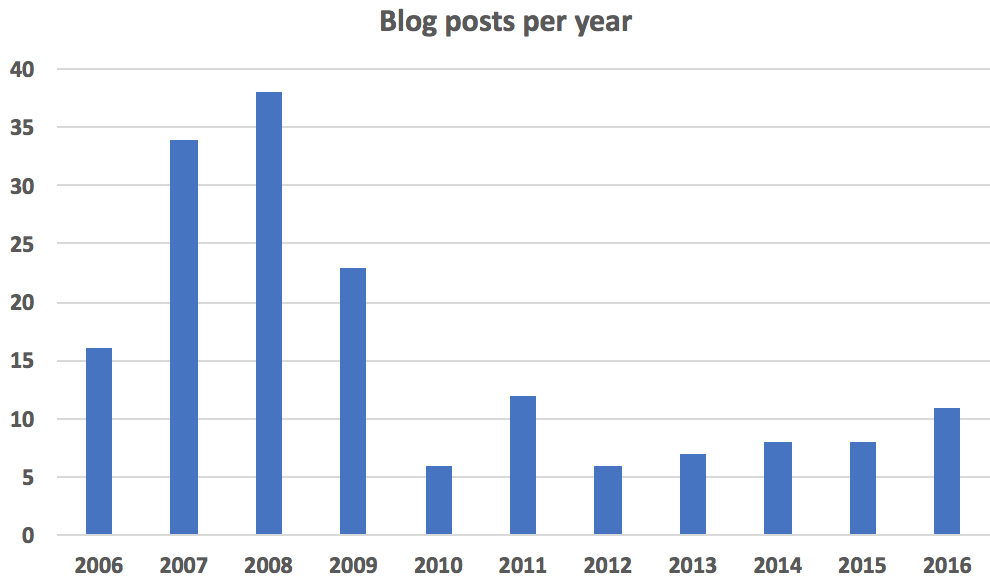
Nevertheless, the amount of blog posts has been very slowly rising. The drop starting around year 2009 very much coincides with me getting onto twitter. Will try to write more in 2017, but we’ll see how that goes. If you have ideas on what I should write about, let me know!
 The amount of readers on the website is basically constant through all the time that I had analytics on it (starting 2013 or
so). Which could mean it’s only web crawling bots that read it, for all I know :) There’s an occasional spike, pretty
much only because someone posted link on either reddit or hackernews, and the hive mind there decided to pay attention
to it for five minutes or whatever.
The amount of readers on the website is basically constant through all the time that I had analytics on it (starting 2013 or
so). Which could mean it’s only web crawling bots that read it, for all I know :) There’s an occasional spike, pretty
much only because someone posted link on either reddit or hackernews, and the hive mind there decided to pay attention
to it for five minutes or whatever.
Giving Back
Financially, I live a very comfortable life now, and that is by no means just an “I made it all by myself” thing. Starting conditions, circumstances, family support, a ton of luck all helped massively.
I try to pay some of that back by sharing knowledge (writing the blog, speaking, answering questions on twitter andask.fm). This is something, but I could do more!
So this year started doing more of a “throw money towards good causes” thing too, compared to what I did before. Helped some local schools, and several local charities / help funds / patreons / “this is a good project” type of efforts. I’m super lucky that I can afford to do that, looking forward to doing more of it in 2017.
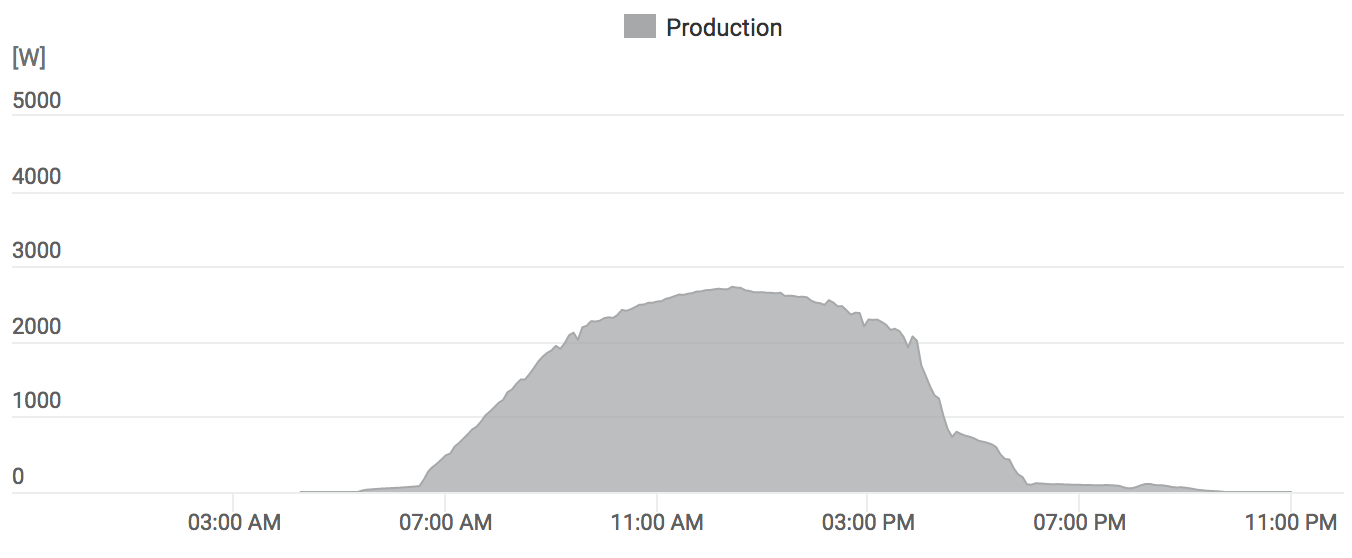
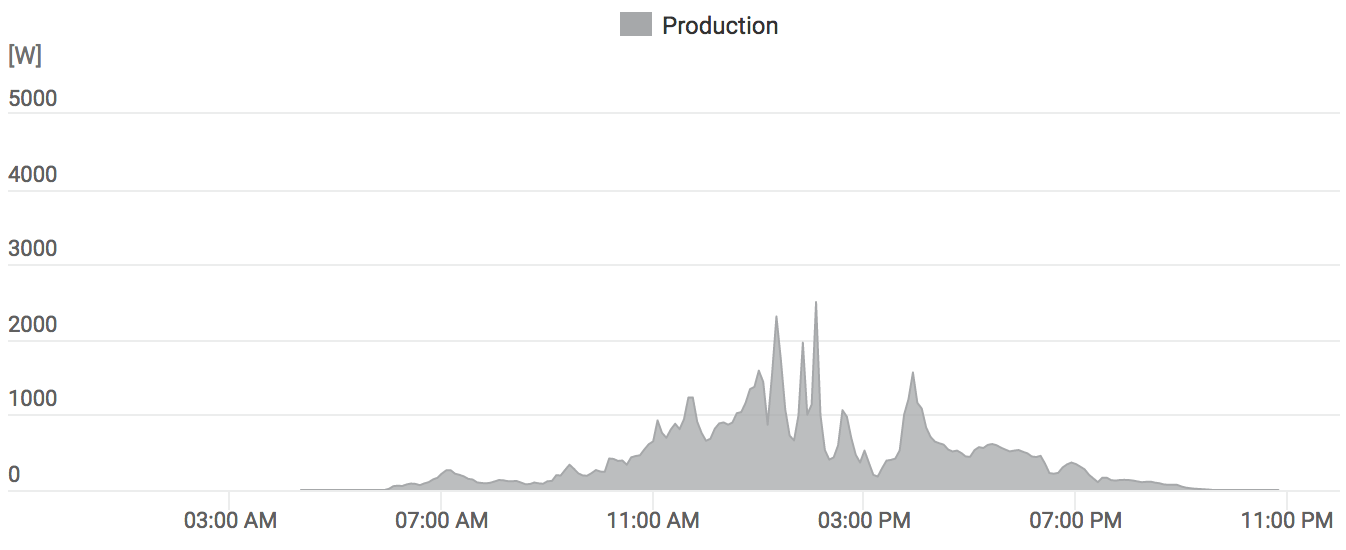
Started work towards installing solar panels on the roof, which should generate about as much electricity as we use up. That’s not exactly under “giving back” section, but feels good to have finally decided to do it. Will see how that goes in our (not that sunny) land.
Other Things
I’m not a twenty-something anymore, and turns out I have to do some sort of extra physical activity besides working with a computer all day long. But OMG it’s so boring, so it takes a massive effort to force myself to do it. I actually stopped going to the gym for half a year, but then my back pains said “ohai! long time no see!”. Ugggh. So towards end of 2016 started doing the gym thing again. I can only force myself to go there twice a week, but that’s enough to keep me from collapsing physically :) So far so good, but still boring.
 Rocksmith keeps on being the only “hobby” that I have, and still having loads of
fun with it. I probably have played about 200 hours this year.
Rocksmith keeps on being the only “hobby” that I have, and still having loads of
fun with it. I probably have played about 200 hours this year.
It feels like I am still improving my guitar playing skills, but I’m not doing enough effort to actually improve. Most of the time I just play through songs in a messy way, without taking time to go through difficult riffs or solos and really nail the things down. So my playing is like: eh, ¯\_(ツ)_/¯. Maybe in 2017 I should try playing with some other people (something I have never done, besides a few very lame attempts in high school), or try taking “real” guitar lessons.
INSIDE and Firewatch are my games of the year. They are both made with Unity too, which does not feel bad at all.
Did family vacations, lazy one in Maldives and a road trip in Spain. Both were nice in their own way, but we all (again) realized that lazy-type vacations are not our style, even if they are nice to have once in a while.
In 2017 I want to spend less time on social media, which lately is mostly a source of really depressing news, and just do more useful or helpful things instead. Wish me luck.