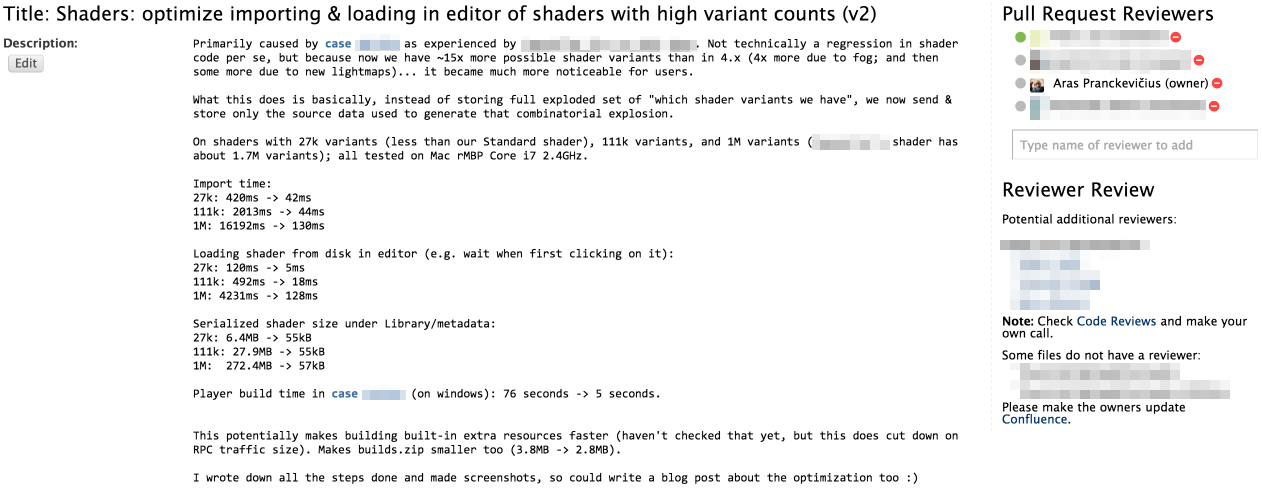
TL;DR: Vulkan SPIR-V shaders are fairly large. SMOL-V can make them smaller.
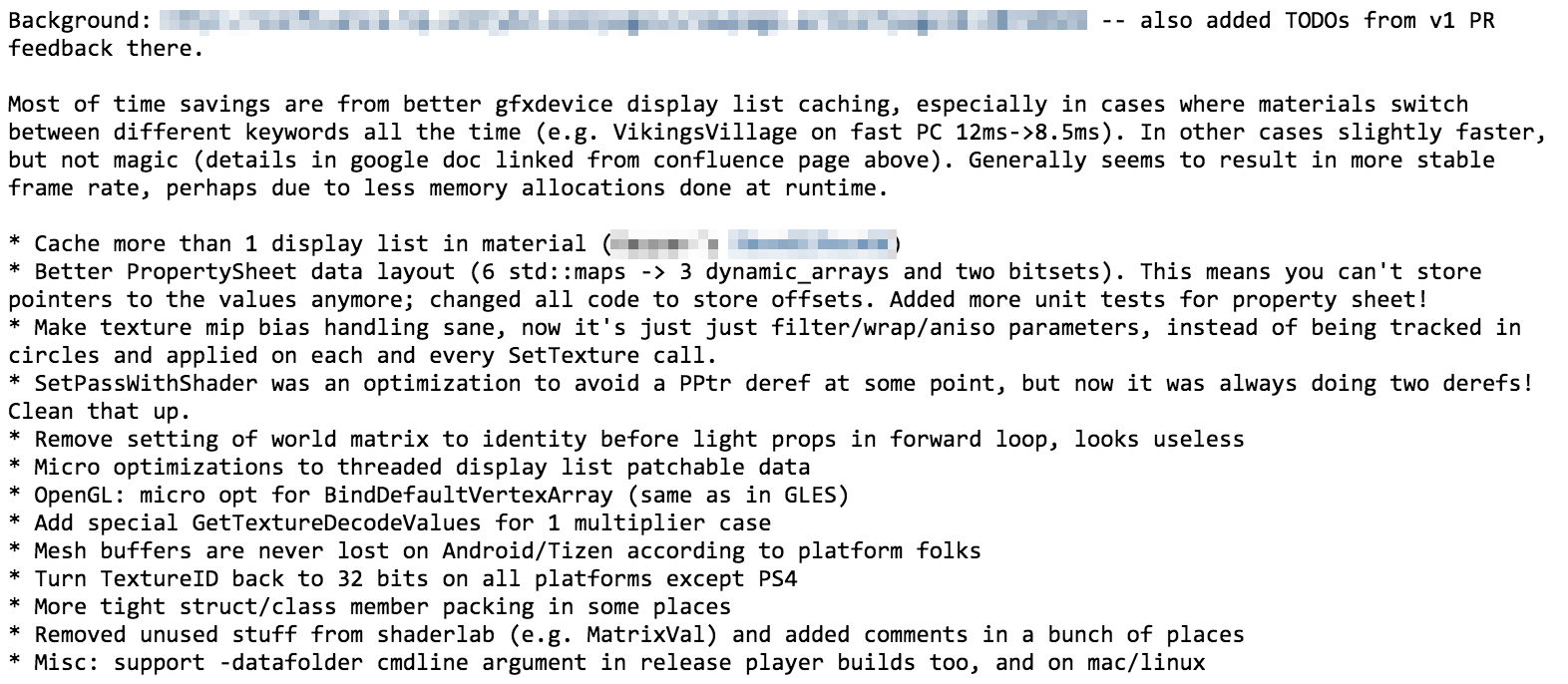
Other folks are implementing Vulkan support at work, and the other day they noticed
that Vulkan shaders (which are represented as SPIR-V binary format)
take up quite a lot of space. I thought it would be a fun excercise to try to make them smoller,
and maybe I’d learn something about compression along the way too.
Caveat emptor! I know nothing about compression. Or rather, I’m probably at the stage
where I can make the impression that I know something about it, but all that knowledge
is very superficial. Exactly the stage that is dangerous, if I start to talk about it as if I have a clue!
So below, I’m doing exactly that. You’ve been warned.
SPIR-V is extremely simple and regular format.
Everything is 4-byte words. Many things that only need a few bits of information are still represented as a word.
This makes it simple, but not exactly space efficient. I don’t have data nearby right now, but a year or so ago
I looked into shaders that do the same thing, compiled for DX9, DX11, OpenGL (GLSL) and Vulkan (SPIR-V), and the SPIR-V
were “fattest” by a large amount (DX9 and minified GLSL being the smallest).
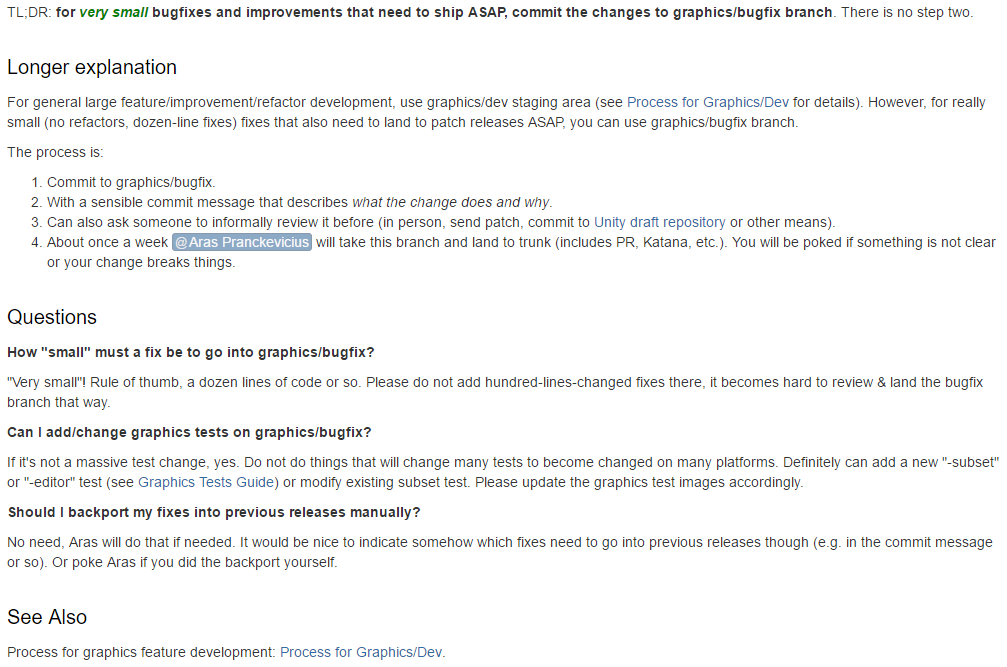
Compressibility
“Why not just compress them?”, you ask. That should take care of these “three bits of information written as 4 bytes”
style enums. That it does; standard lossless compression techniques
are pretty good at encoding often occuring patterns into a small number of bits (further reading:Huffman, Arithmetic,FSE coding).
And indeed, SPIR-V compresses quite well. For example, 1315 kilobytes worth of shader data (from various Unity shaders)
compresses to 279 kilobytes with Zstandard and to 306 kilobytes withzlib (I used miniz implementation) at default settings. So a standard go-to
compression (zlib) gets you a 23.4% compression of SPIR-V.
However, SPIR-V is full of not-really-compressible things, mostly various identifiers (anything called <id> in thespec). Due to theSSA form that SPIR-V uses, all the identifiers
ever used are unique numbers, with nothing reusing a previous ID. A regular data compressor does not get to see
many repeating patterns there.
Data compression algorithms usually only look for literally repeating patterns.
If you’d have a file full of 0x00000001 integers, this will compress extremely well. However,
if your file will be a really simple sequence of integers: 1, 2, 3, 4, …, this will not compress
particularly well!
I actually just tested this. 16384 four-byte words, which are just a sequence of 0,1,…,16383 integers, compressed
with zlib at default settings: 64KB -> 22716 bytes.
Enter Data Filtering
Recall that “a simple sequence of numbers compresses quite poorly” example above? Turns out, a typical trick in
data compression is to filter the data before compressing it. Filtering can be any sort of reversible transformation
of the data, that makes it be more compressible, i.e. have more actually repeating patterns.
For example, using delta encoding on that integer sequence would transform
it into a file that is pretty much all just 0x00000001 integers. This compresses with zlib into just 88 bytes!
Data filtering is fairly widely used, for example:
- PNG image format has several filters, as described here.
- Executable file compression usually transforms machine code instructions into a more compressible form, seetechniques used in .kkrunchy for example.
- HDF5 scientific data format has filters likebitshuffle that reorder data before actual compression.
- Some compressors like RAR seemingly automatically apply various filters to data blocks they identify
as “filterable” (i.e. “looks like an executable” or “looks like sound wave samples” somehow).
Perhaps we could do some filtering on SPIR-V to make it more compressible?
Filtering: spirv-remap
In SPIR-V land, there is a tool called spirv-remap
that aims to help with compression. What it does, is it changes all the IDs used in the shader to values that would hopefully
be similar if you have a lot of other similar shaders, and compress them all as a whole. For each new ID, it “looks” at
several surrounding instructions, and picks the ID based on their hash.
The assumption is that you’re very likely to have other shaders that have similar fragments of instructions – they would
be compressible if only the IDs would be the same.
And indeed, on that same set of shaders I had above: uncompressed size 1315KB, zstd-compressed 279KB (21.2%), remapped + zstd
compressed: 189KB (14.4% compression).
However, spirv-remap tries to filter the SPIR-V program in a way that still results in a valid SPIR-V program. Maybe we could do
better, if we did not have such a restriction?
SMOL-V: making SPIR-V smoller
So that’s what I did. My goal was to conceptually have two functions:
ByteArray Encode(const ByteArray& spirvInput); // SPIR-V -> SMOL-V
ByteArray Decode(const ByteArray& encodedBytes); // SMOL-V -> SPIR-V
with the goal that:
- Encoded result would be smaller than input,
- When compressed (with Zstd, zlib etc.), it would be smaller than if I just compressed the input,
- When compressed, it would be smaller than what a compressed spirv-remap can achieve.
- Do that in a fairly simple way. Since hey, I’m a compression n00b, anything that is compression rocket surgery is likely way
out of my capabilities. Also, I wanted to roughly spend a (long) day on this.
So below is a write up of what I did (can also be seen in the commit history).
First of all, I just looked at the SPIR-V binaries with a hex viewer. And in almost every step below,
either looked at binaries, or printed bytes of instructions and looked for patterns.
Variable-length integer encoding: varint
Recall that SPIR-V uses four-byte words to store every single piece of information it needs. Often these are enum-style
information that uses a few dozen possible values. I did not want to hardcode every possible operation & enum ranges
(that would be a lot of work, and not very future-proof with later SPIR-V versions), so instead I looked at various
variable-length integer storage schemes. Most famous is probably UTF-8 in text
land. In binary data land there are VLQ,LEB128 and varint,
which all are variations of “store 7 bits of data, and one bit to signal if there are more bytes following”. I picked
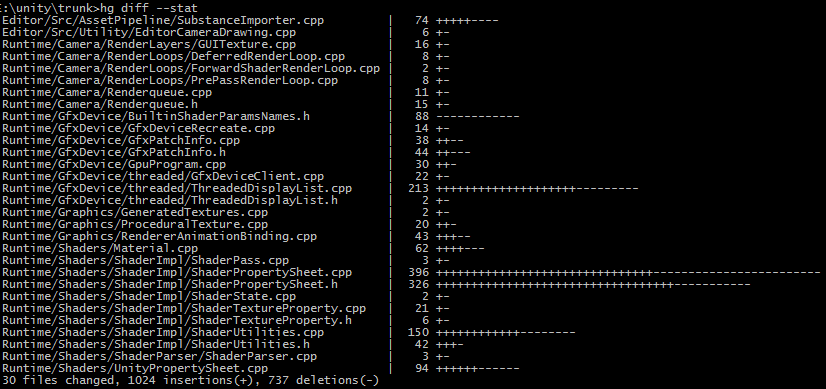
the “varint” as used by Google Protocol Buffers, if only because I found it before I found the others :)
With varint encoding for unsigned integers, numbers below 128 take only one byte, numbers below 16384 take two
bytes and so on.
So the very first try was to use varint encoding on each instruction’slength+opcode word, and the Type ID
that many instructions have. Then I noticed that the Result IDs
of almost every instructions are just one or two IDs larger then the result of a previous instruction. So I wrote them out
as deltas from previous, and again encoded as varint.
This got just SMOL-V data to 71% size of original SPIR-V, and 18.2% when Zstd-compressed on top.
Relative-to-result and varint on often-occurring instructions
I dumped frequencies of how much space various opcode types take, and it became fairly clear that OpDecorate takes a lot, as well asOpVectorShuffle.
Now, decorations are guaranteed to be grouped,
and often are specified on the same or very similar target IDs. The decoration values themselves are small integers. So,
encode result IDs relative to a previously seen declarations, and use varint encoding on everything else
(commit).
Vector shuffles also specify several IDs (often close to just-seen ones), and a few small component indices, so do a similar
treatment for that (commit).
Combined, these took SMOL-V data to 56%, and 14.6% when Zstd-compressed.
I then noticed that the same pattern occurs in a lot of other instructions: the opcode, type and result IDs are often followed
by several other IDs (how many depends on the opcode), and some other “usually small integer” values (how many, again depends
on the opcode). So instead of just hardcoding handling of these several opcodes above, I generalized the code to look
up this information into a table indexed by opcode.
After quite a lot more opcodes got this treatment, I was at 42% SMOL-V size, and 10.7% when Zstd-compressed. Not bad!
Negative deltas?
Most of the ID arguments I have encoded as a delta from previous Result ID value. The deltas were
always positive so far, which is nice for varint encoding. However when I came to adding the same treatment to branch and
control flow instructions, I realized that the IDs they reference are often“in the future”, which would mean the deltas are negative. Under the varint encoding, these would be the same as very large
positive numbers, and often encode into 4 or 5 bytes.
Luckily, the same Protocol Buffers have a solution for that; signed integers get their bits shuffled so that small absolute values
are turned into small positive values – theZigZag encoding. So I used that to encode IDs
of control flow instructions.
Opcode value reordering
At this point tweaking just delta+varint encoding was starting to give diminishing returns. So I started looking at bytes again.
That “encode opcode + length as varint” was often producing 2 or 3 bytes worth of data, due to the way SPIR-V encodes that word.
I tried reordering it so that most common opcodes&lenghts produce just one byte.
1) Swap opcode values so that most common ones fit into 4 bits. Most common ones in my shader test data were: Decorate (24%), Load (17%), Store (9%), AccessChain (7%), VectorShuffle (5%), MemberDecorate (4%) etc.
static SpvOp smolv_RemapOp(SpvOp op)
{
# define _SMOLV_SWAP_OP(op1,op2) if (op==op1) return op2; if (op==op2) return op1
_SMOLV_SWAP_OP(SpvOpDecorate,SpvOpNop); // 0
_SMOLV_SWAP_OP(SpvOpLoad,SpvOpUndef); // 1
_SMOLV_SWAP_OP(SpvOpStore,SpvOpSourceContinued); // 2
_SMOLV_SWAP_OP(SpvOpAccessChain,SpvOpSource); // 3
_SMOLV_SWAP_OP(SpvOpVectorShuffle,SpvOpSourceExtension); // 4
// Name - already small value - 5
// MemberName - already small value - 6
_SMOLV_SWAP_OP(SpvOpMemberDecorate,SpvOpString); // 7
_SMOLV_SWAP_OP(SpvOpLabel,SpvOpLine); // 8
_SMOLV_SWAP_OP(SpvOpVariable,(SpvOp)9); // 9
_SMOLV_SWAP_OP(SpvOpFMul,SpvOpExtension); // 10
_SMOLV_SWAP_OP(SpvOpFAdd,SpvOpExtInstImport); // 11
// ExtInst - already small enum value - 12
// VectorShuffleCompact - already small value - used for compact shuffle encoding
_SMOLV_SWAP_OP(SpvOpTypePointer,SpvOpMemoryModel); // 14
_SMOLV_SWAP_OP(SpvOpFNegate,SpvOpEntryPoint); // 15
# undef _SMOLV_SWAP_OP
return op;
}
2) Adjust opcode lengths so that most common ones fit into 3 bits.
// For most compact varint encoding of common instructions, the instruction length
// should come out into 3 bits. SPIR-V instruction lengths are always at least 1,
// and for some other instructions they are guaranteed to be some other minimum
// length. Adjust the length before encoding, and after decoding accordingly.
static uint32_t smolv_EncodeLen(SpvOp op, uint32_t len)
{
len--;
if (op == SpvOpVectorShuffle) len -= 4;
if (op == SpvOpVectorShuffleCompact) len -= 4;
if (op == SpvOpDecorate) len -= 2;
if (op == SpvOpLoad) len -= 3;
if (op == SpvOpAccessChain) len -= 3;
return len;
}
static uint32_t smolv_DecodeLen(SpvOp op, uint32_t len)
{
len++;
if (op == SpvOpVectorShuffle) len += 4;
if (op == SpvOpVectorShuffleCompact) len += 4;
if (op == SpvOpDecorate) len += 2;
if (op == SpvOpLoad) len += 3;
if (op == SpvOpAccessChain) len += 3;
return len;
}
3) Interleave bits of the original word so that these common ones (opcode + lenght) take up lowest
seven bits of the result, and encode to just one byte in varint scheme. 0xLLLLOOOO is how SPIR-V
encodes it (L=length, O=op), shuffle it into 0xLLLOOOLO so that common case (op<16, len<8) is encoded
into one byte.
That got things down to 35% SMOL-V size, and 9.7% when Zstd-compressed.
Vector Shuffle encoding
SPIR-V has a single opcode OpVectorShuffle
that is used for both selecting components from two vectors, and for a typical “swizzle”. Swizzles are by far the most
common in the shaders I’ve seen, so often in raw SPIR-V something like “v.xxyy” swizzle ends up being “v, v, 0, 0, 1, 1” -
each of these being a full 32 bit word (both arguments point to the same vector, and then component indices spelled out).
I made the code recognize this common pattern of “shuffle with <= 4 components, where each is between 0 and 3”, and encode that
as a fake “VectorShuffleCompact” opcode using one of the unused opcode values, 13. The swizzle pattern fits into one byte
(two bits per channel) instead taking up 16 bytes (commit).
Adding non-Unity shaders, and zigzag
At this point I added more shaders to test on, to see how everything above behaves on non-Unity compilation pipeline produced
shaders (thanks @baldurk, @AlenL and@basisspace for providing and letting me use shaders from The Talos Principle and DOTA2).
Turns out, both of these games ship with shaders that are alreayd processed with spirv-remap. One thing it does
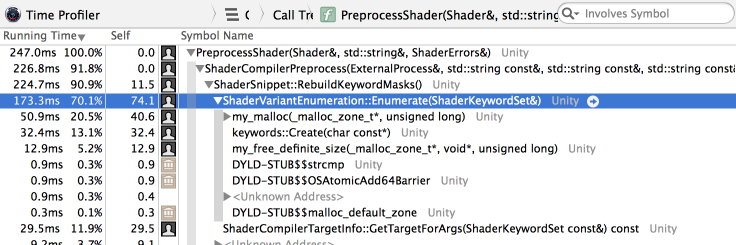
(well, the primary thing it does!) is changing all the IDs to not be linearly increasing, but have values all over the place.
My previous work on using delta encoding and varint output was often going against that, since often it would be that next ID
would be smaller than previous one, resulting in negative delta, which encodes into 4 or 5 bytes under varint. Not good!
Well it wasn’t bad; this is SMOL-V that not only compresses, but also strips debug info, to match what spirv-remap
did for Talos/DOTA2 case:
- Unity: remap+zstd 13.0%, SMOL-V+zstd 7.2%.
- Talos: remap+zstd 11.1%, SMOL-V+zstd 9.0%.
- DOTA2: remap+zstd 9.9%, SMOL-V+zstd 8.4%.
It already compresses better than spirv-remap, but is more better on shaders that aren’t already remapped.
I switched all the deltas to use zigzag encoding (see Negative Deltas above), so that on already remapped shaders
it does not go into “whoops encoded into 5 bytes”:
- Unity: remap+zstd 13.0%, SMOL-V+zstd 7.3% (a tiny bit worse than 7.2% before).
- Talos: remap+zstd 11.1%, SMOL-V+zstd 8.5% (yay, was 9.0% before).
- DOTA2: remap+zstd 9.9%, SMOL-V+zstd 8.2% (small yay, was 8.4% before).
MemberDecorate encoding
Structure/buffer decorations (OpMemberDecorate)
were taking up quite a bit of space, so I looked for some patterns in them.
Most often they are very simple sequences, e.g.
Op Type Member Decoration Extra
MemberDecorate 168 0 35 0
MemberDecorate 168 1 35 64
MemberDecorate 168 2 35 80
MemberDecorate 168 3 35 96
MemberDecorate 168 4 35 112
MemberDecorate 168 5 35 128
MemberDecorate 168 6 0
MemberDecorate 168 6 35 384
MemberDecorate 168 7 35 400
When encoding, I scan ahead to see whether there’s a sequence of MemberDecorate instructions that are all about the same
type, and “fold” them into one – so I can skip writing out opcode+lenght and type ID data. Additionally, delta encode
member index, and have special handling of decoration 35 (“Offset”, which is extremely common) to store actual offset
as delta from previous one. This got some gains (commit).
Quite likely OpDecorate sequences could
get a similar treatment, but I did not do that yet.
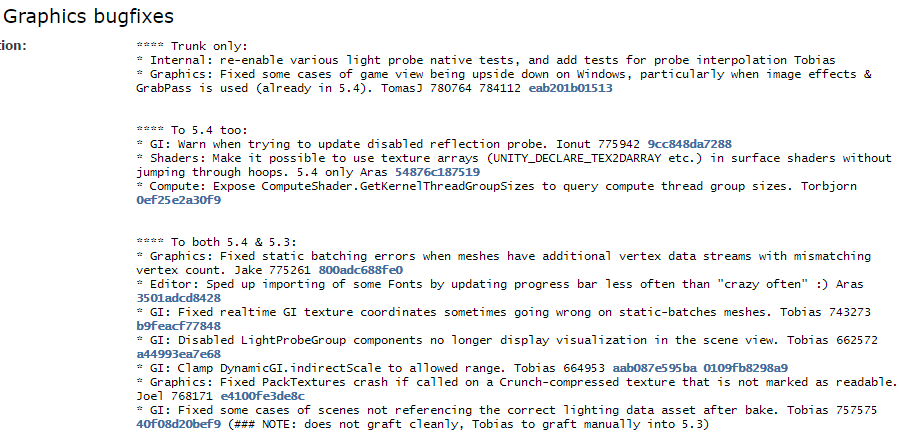
Current status
So that’s about it! Current compression numbers, on a set of Unity+Talos+DOTA2 shaders, with debug info stripping:
| Compression | No filter (*) | spirv-remap | SMOL-V |
|---|
| Size KB | Ratio | Size KB | Ratio | Size KB | Ratio |
|---|
| Uncompressed | 3725.4 | 100.0% | 3560.0 | 95.6% | 1297.6 | 34.8% |
| zlib default | 860.6 | 23.1% | 761.9 | 20.5% | 464.9 | 12.5% |
| LZ4HC default | 884.4 | 23.7% | 743.3 | 20.0% | 441.0 | 11.8% |
| Zstd default | 555.4 | 14.9% | 425.6 | 11.4% | 295.5 | 7.9% |
| Zstd level 20 | 339.4 | 9.1% | 260.5 | 7.0% | 226.7 | 6.1% |
(*) Note: about 2/3rds of the shader (Talos & DOTA2) set were already processed by spirv-remap; I don’t have unprocessed shaders from these games.
This makes spirv-remap look a bit worse than it actually is though.
I think it’s not too bad for a couple days of work. And I have learned a thing or two about compression.
Again, the github repository is here: github.com/aras-p/smol-v.
- Encoding does a simple one-pass scan over the input (with occasional look aheads for MemberDecorate sequences), and
writes encoded result to the output.
- Decoding simply goes over encoded bytes and transforms into SPIR-V. One pass over data, no memory allocations.
- No “altering” of SPIR-V programs is done; what you encode is exactly what you get after decoding (this is different from spirv-remap, that
actually changes the IDs). Exception is the
kEncodeFlagStripDebugInfo that removes debug information from the input program.
Future Work?
Not sure I will work on this much (as opposed to “eh, good enough for now”), but possible future work might be:
- Someone who actually knows about compression will look at it, and point out low hanging fruits :)
- Do special encoding of some more opcodes (OpDecorate comes to mind).
- Split up encoded data into several “streams” for better compression (e.g. lenghts, opcodes, types, results, etc.). Very similar
to the “Split-stream encoding” from .kkrunchy blog post.
- As John points out, there are other possible axes to
explore compression.
This was super fun. I highly recommend “short, useful, and you get to learn something” projects :)
![]()